
防偽查詢
QQ在線
聯系方式
深圳市豹點科技有限公司
地 址:深圳市南山區桃園路
田廈國際中心B座1235
郵 編:518052
聯系人:李先生
電 話:189 4870 7815
手 機:189 2467 2967
傳 真:0755-8670 3785
E-mail:felix411@cnbaod.com
網 址:www.cnbaod.com
 內容編輯
內容編輯如今,機器學習算法被廣泛用于制造無人駕駛汽車中出現的,各種挑戰性的解決方案。通過在汽車中的ECU(電子控制單元)中結合傳感器處理數據,有必要提高機器學習的利用以完成新任務。
潛在的應用包括通過來自不同外部和內部傳感器(如激光雷達,雷達,攝像頭或物聯網)的數據融合來評估駕駛員狀況或駕駛場景分類。
運行汽車信息娛樂系統的應用程序可以從傳感器數據融合系統接收信息,例如,如果車輛注意到駕駛員受傷,則可以將汽車引導到醫院。這種基于機器學習的應用程序還包括駕駛員的言語和手勢識別和語言翻譯。
算法分為無監督和監督算法,兩者之間的區別是他們如何學習。
監督算法利用訓練數據集學習,并繼續學習,直到達到他們所期望的(最小化錯誤概率)程度。監督算法可以分為歸類,分類和異常檢測或維數縮減。
無監督算法嘗試從可用數據中導出值。這意味著,在可用數據內,算法產生關系,以便檢測模式或根據它們之間的相似程度,將數據集劃分為子組。無監督算法可以在很大程度上被分類為關聯規則學習和聚類。
加強算法是另一組機器學習算法,它處于無監督和監督學習之間。對于每個訓練示例,在監督學習中有一個目標標簽; 在無監督的學習中完全沒有標簽; 強化學習包括時間延遲和稀疏標簽 - 未來的獎勵。
代理學習根據這些獎勵在環境中的行為。了解算法的局限性和優點,并開發高效的學習算法是強化學習的目標。強化學習可以解決大量實際應用,從AI的問題到控制工程或操作研究,這些都與開發自駕車相關。這可以分為間接學習和直接學習。
在自主汽車中,機器學習算法的主要任務之一是連續渲染周圍環境,并預測可能對這些環境造成的變化。這些任務分為4個子任務:
檢測對象識別對象或識別對象分類物體定位與運動預測
機器學習算法被寬泛地分為4類:決策矩陣算法,集群算法,模式識別算法和回歸算法。可以利用一類機器學習算法來完成2個以上的子任務。例如,回歸算法可以用于對象定位以及對象檢測或運動預測。
決策矩陣算法
決策矩陣算法系統地分析,識別和評估信息集和值之間關系的表現。這些算法主要用于決策。汽車是否需要制動或左轉是基于這些算法對物體的下一次運動的識別,分類和預測的置信度。決策矩陣算法是由獨立訓練的各種決策模型組成的模型,在某些方面,將這些預測結合起來進行總體預測,同時降低決策中錯誤的可能性。
AdaBoosting
AdaBoosting是最常用的算法。自適應提升或AdaBoost是可以用于回歸或分類的多種學習算法的組合。與任何其他機器學習算法相比,它克服了過度擬合,并且通常對異常值和噪聲數據敏感。為了創建一個復合強大的學習者,AdaBoost使用多次迭代。
因此,它可以很好的適應。通過迭代添加弱勢學習者,AdaBoost創造了一個強大的學習者。一個新的弱學習者被附加到實體和權衡載體,以調整被之前幾輪錯誤分類的例子。結果是,具有比弱學習者的分類器高得多的分類器。
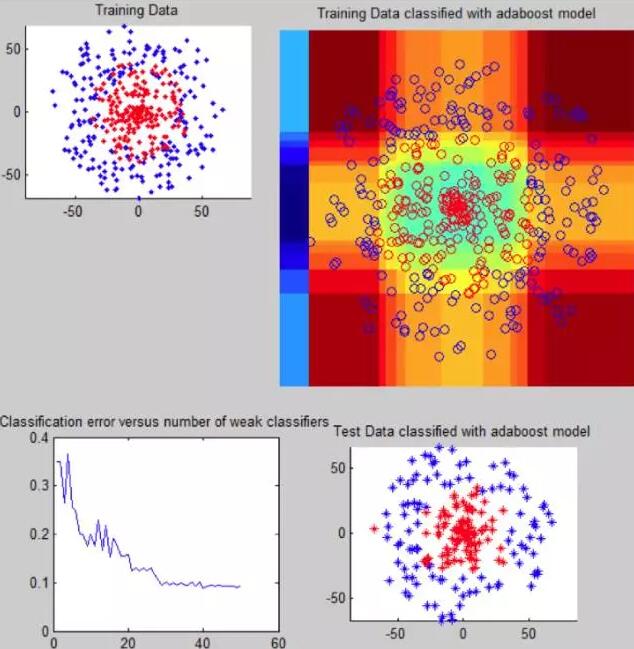
AdaBoost有助于將弱閾值分類器提升為強分類器。上面的圖像描繪了AdaBoost在一個可以理解的代碼的單個文件中的實現。該函數包含一個弱分類器和boosting組件。
弱分類器嘗試在數據維度之一中定位理想閾值,將數據分為2類。分類器通過迭代部分調用,并且在每個分類步驟之后,它改變了錯誤分類示例的權重。正因為如此,創建弱分類器的級聯行為就像一個強分類器。
聚類算法
有時,由系統獲取的圖像不清楚,難以定位和檢測對象。有時,分類算法有可能丟失對象,在這種情況下,它們無法對系統進行分類并將其報告給系統。可能的原因可能是不連續數據,非常少的數據點或低分辨率圖像。
聚類算法專門從數據點發現結構。它描述了類的方法和類的問題,如回歸。聚類方法通常通過對分層和基于質心的方法進行建模來組織。所有方法都關注利用數據中的固有結構將數據完美地組織成最大共性的組。
K-means
K-means—多類神經網絡是最常用的算法,是一個著名的聚類算法。K-means存儲它用于定義集群的k質心。如果一個點比任何其他質心更接近該集群的質心,那么這個點被說成是在一個特定的集群中。通過根據當前分配數據點到集群和根據當前質心將數據點分配給集群,選擇質心之間進行交替。
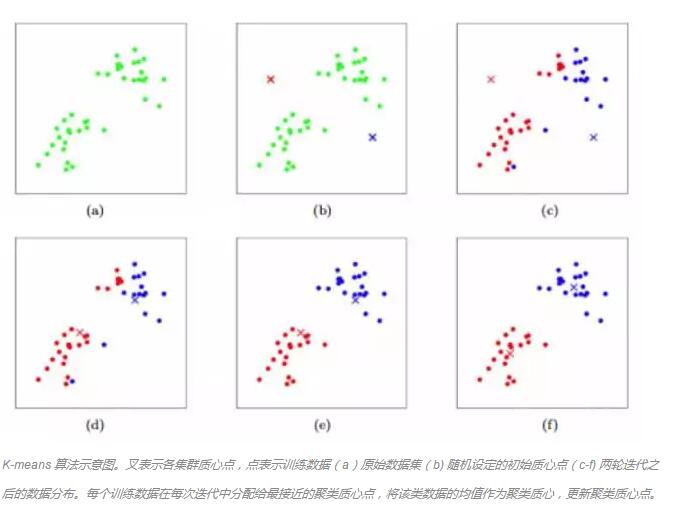
K均值算法 - 簇重心被描繪為十字,訓練示例被描繪為點。(a)原始數據集。(b)隨機初始聚類中心。(cf)運行2次k-means迭代的演示。每個訓練示例在每個迭代中分配給最接近的聚類中心,然后將每個聚類中心移動到分配給它的點的平均值。
模式識別算法(分類)
通過高級駕駛輔助系統(ADAS)中的傳感器獲得的圖像由各種環境數據組成; 需要過濾圖像以通過排除不相關的數據點來確定對象類別的實例。在分類對象之前,模式的識別是數據集中的重要一步。這種算法被定義為數據簡化算法。
數據簡化算法有助于減少對象的數據集邊緣和折線(擬合線段)以及圓弧到邊緣。直到一個角落,線段與邊緣對齊,并在此之后開始一個新的線段。圓弧與類似于弧的線段的序列對齊。以各種方式,將圖像的特征(圓弧和線段)組合以形成用于確定對象的特征。
**支持向量機(SVM) **
PCA(原理分量分析)和HOG(定向梯度直方圖),支持向量機(Support Vector Machines,支持向量機)是ADAS中常用的識別算法。還使用K個最近鄰(KNN)和貝葉斯決策規則。
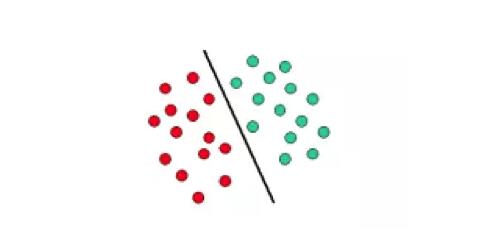
SVM依賴于定義決策界限的決策平面概念。決策平面分離由不同的類成員組成的對象集。下圖給出了示意性示例。在這里,對象屬于RED或GREEN類。分離邊界線將紅色和綠色物體分開。任何落在左側的新對象都標記為RED,如果它落在左邊,則將其標記為GREEN。
回歸算法
這種算法有利于預測事件。回歸分析評估2個或更多個變量之間的關系,并將變量的影響整理到不同的量表上,主要由3個指標驅動:
回歸線的形狀因變量的類型自變量的數量
圖像(攝像機或雷達)在啟動和定位中在ADAS中起著重要作用,而對于任何算法,最大的挑戰是開發基于圖像的特征選擇和預測模型。
通過回歸算法來利用環境的重復性,以創建給定對象在圖像中的位置與該圖像之間的關系的統計模型。統計模型,通過允許圖像采樣,提供快速在線檢測,可以離線學習。它可以進一步擴展到其他對象,而不需要廣泛的人造型。對象的位置由算法返回,作為在線階段的輸出和對對象存在的信任。
回歸算法也可以用于短期預測,長期學習。可以用于自動駕駛的這種回歸算法是決策林回歸,神經網絡回歸和貝葉斯回歸等。
神經網絡回歸
神經網絡用于回歸,分類或無監督學習。他們對未標記的數據進行分組,對數據進行分類或在監督培訓后對連續值進行預測。神經網絡通常在網絡的最后一層使用邏輯回歸的形式,將連續數據變為1或0變量。
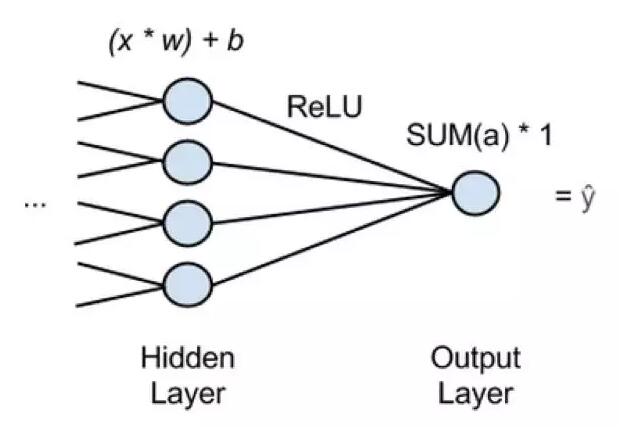
在上圖中,“x”是輸入,從網絡上一層傳出的特征。進入最后一層隱藏層的每一個節點,將饋送許多x,并將每個x乘以w,相應的權重,產品的總和被添加并移動到激活功能。
激活功能是ReLU(整流線性單元),通常用于像Sigmoid激活功能,在淺梯度上不飽和。ReLU為每個隱藏節點提供一個輸出,激活a,并且激活被添加到通過激活和的輸出節點中。
這意味著,執行回歸的神經網絡包含單個輸出節點,并且該節點將先前層的激活總和乘以1.網絡的估計“y hat”將是結果。'Y hat'是所有x映射到的因變量。您可以以這種方式使用神經網絡來獲取與您嘗試預測的y(一個因變量)相關的x(自變量)。
(本文來源于微信公眾號機械雞)